垃圾佬的终极形态?用捡来的硬件,部署一个懂你一切的本地AI助理
这段时间AI有多火,不用我多说了吧?无论是写代码、写文案,还是做图,好像离了它就不会干活了似的。
但咱们“垃圾佬”群体,向来是实用主义至上。看着国内外那些大模型动不动一个月一百多块软妹币的订阅费,心里总归是不是滋味。更关键的是,你真的放心把你硬盘里那点“学习资料”、私密文档,甚至是你公司的代码,一股脑全传到别人的云端服务器上?
今天,咱们不聊怎么捡漏几百块的NUC,咱们来聊个更刺激的——怎么利用手头的“电子垃圾”,搓一个完全属于你自己的、绝对隐私的“赛博义肢”:Clawbot(抓手机器人)私人AI助理。

01 什么是Clawbot?为什么你需要它?
先澄清一下,“Clawbot”不是某个具体硬件产品的名字,而是我对下一代私人AI助理形态的一种称呼。
现在的ChatGPT、Claude,更像是“先知”,你问它答,但他不了解你,也无法触碰你的数字生活。
而Clawbot,是你部署在本地硬件上的一个Agent(智能体)。它就像一只无形的手,能伸进你的硬盘、你的Obsidian笔记、你的浏览器历史记录里,帮你“抓取”信息,整理思路,甚至执行操作。
最重要的是,这一切都在你的局域网内发生,连根网线拔了它照样能跑。
对于我们这种控制欲极强、又抠门的数码玩家来说,这才是AI该有的样子:
- 0订阅费: 一次投入硬件,终身白嫖算力。
- 绝对隐私: 你的数据永远不出家门。
- 无限对话: 没有什么“每3小时限制40条”,想怎么聊就怎么聊。
02 垃圾佬的军火库:跑起AI需要什么?
很多人被营销号忽悠瘸了,以为跑本地AI非得要几万块的H100或者4090。
扯淡。咱们是谁?咱们是用最少钱办大事的垃圾佬。2026年的今天,开源社区已经把大模型的门槛打下来了。

要搓出这台Clawbot,核心是显存(VRAM)和内存。以下是几种咱们圈子里的经典捡漏方案:
-
入门级(尝鲜体验):
你手里那台3060 12G就是永远的神!12G显存足够跑起量化后的8B(80亿参数)模型,比如Llama 3或者Qwen的最新小参数版本。响应速度嗖嗖的,日常对话、简单代码辅助完全够用。
-
进阶级(垃圾佬最爱):
Tesla P40 24G 或者魔改版的 2080Ti 22G。这简直是为AI而生的“大显存垃圾”。虽然只能跑推理(用它训练你会疯掉),但配合合适的平台,跑个中等规模的还是没问题的。几百块买24G显存,还要什么自行车?
-
纯CPU党(量大管饱):
如果你有退役的服务器E5洋垃圾,或者内存插满128G的DDR4平台。虽然速度慢点,但你可以用纯CPU模式硬跑一些参数更大的模型。慢是慢了点,但它能聊得更深啊。
划重点: 甚至上期咱们聊的那个百元NUC,只要内存够,跑个极小参数的模型当个智能终端也没问题!
03 灵魂注入:软件栈才是关键
硬件搭好了,怎么让它动起来?
别怕,现在早就不需要你一行行敲Python代码了。2026年的本地AI生态,简直傻瓜到家了。
我目前最推荐的“Clawbot”软件组合拳是:Ollama + AnythingLLM/Open WebUI。
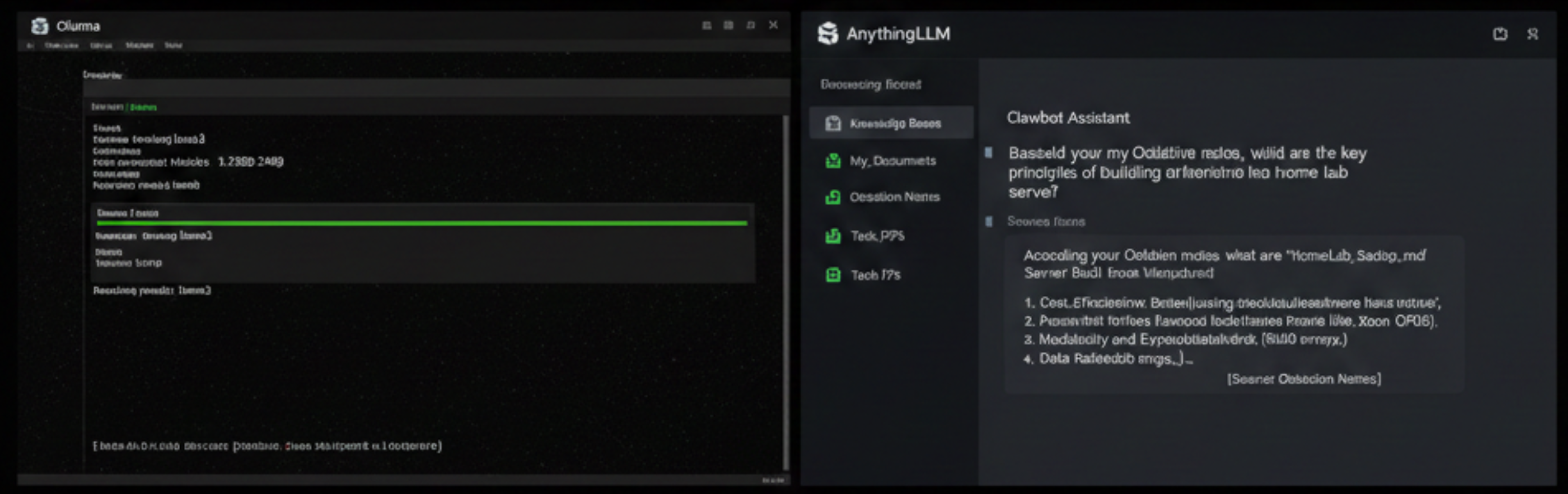
- Ollama(发动机): 一个命令行工具,一句
ollama run llama3,模型就自动下载并在后台跑起来了,提供了标准的API接口。 - AnythingLLM(大脑与抓手): 这就是Clawbot的灵魂。这是一个带有RAG(检索增强生成)功能的Web界面。
什么叫RAG? 简单说,就是你可以把你这几年攒下来的几百个PDF技术文档、几千条Obsidian笔记,直接拖进AnythingLLM里。它会自动建立索引。
接下来你再问AI问题,它就不是瞎编了,而是会先去“抓取(Claw)”你资料库里的内容,结合这些内容给你回答。
这才是真正的“私人助理”!它读过你读过的书,走过你走过的路,爱你爱过的人,懂你的黑话。
04 总结:折腾的乐趣
当然,搭建Clawbot的过程肯定没有直接充钱买会员来得快。你需要折腾驱动、需要研究不同量化版本的区别、需要调试Prompt。
但对于咱们数码爱好者来说,折腾本身不就是最大的乐趣吗?
当那行绿色的光标在屏幕上跳动,输出着只属于你自己的、带着你个人知识库印记的文字时,那种成就感,是任何云端服务都给不了的。
不要让AI成为你的替代者,要让它成为你手里最锋利的工具。
兄弟们,翻翻你们的零件箱,Clawbot搞起来!
今日互动:
你手头现在闲置显存最大的显卡是哪一张?准备拿它来跑哪个模型?评论区聊聊,优秀的方案我下期直接抄作业!